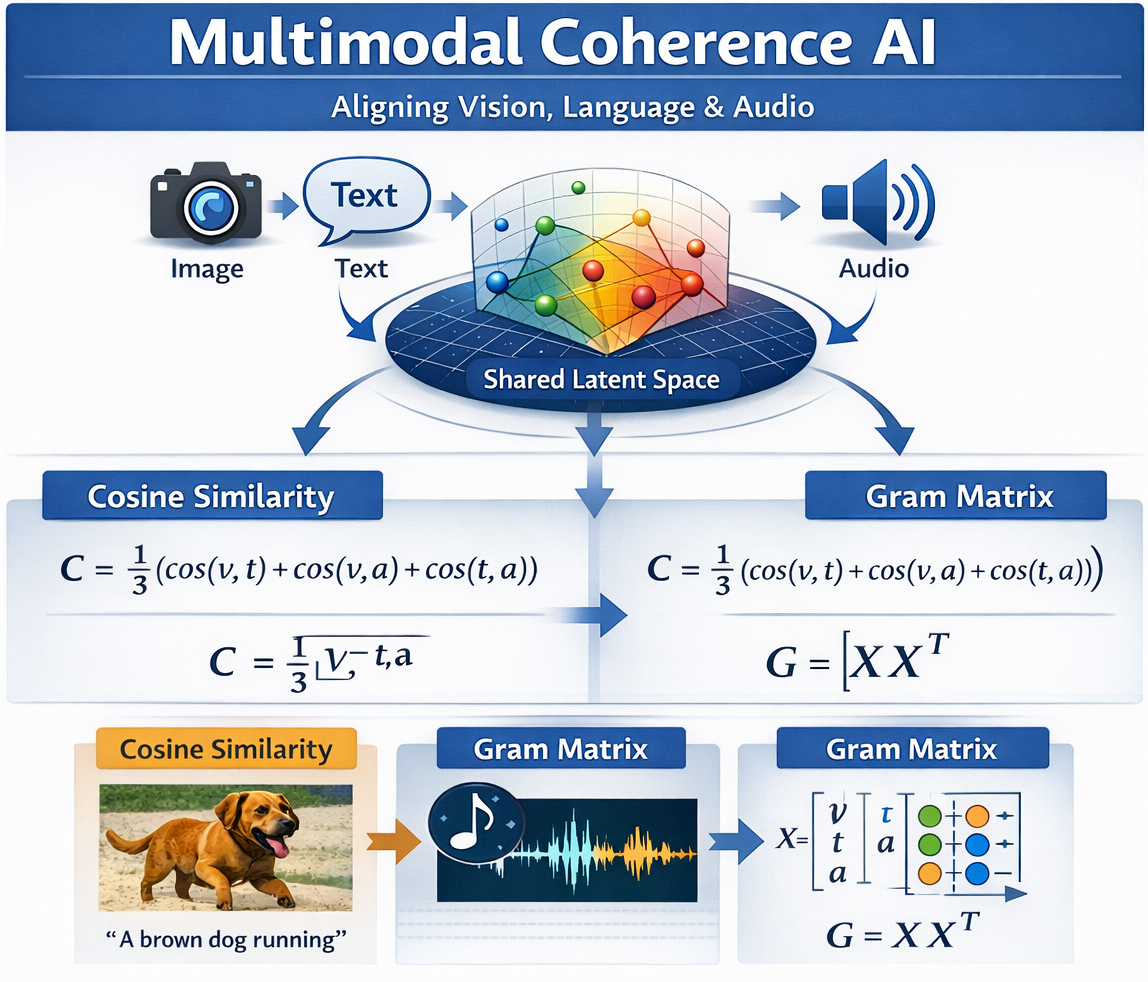
MultiModal Coherence AI is an interactive research-driven application that demonstrates how artificial intelligence can evaluate and model coherence across multiple modalities — including text, audio, and visual representations. The system is designed to move beyond simple pairwise similarity by leveraging advanced geometric and contrastive alignment techniques to project heterogeneous modalities into a shared representation space. This enables more robust and interpretable cross-modal reasoning compared to traditional cosine-based averaging methods.
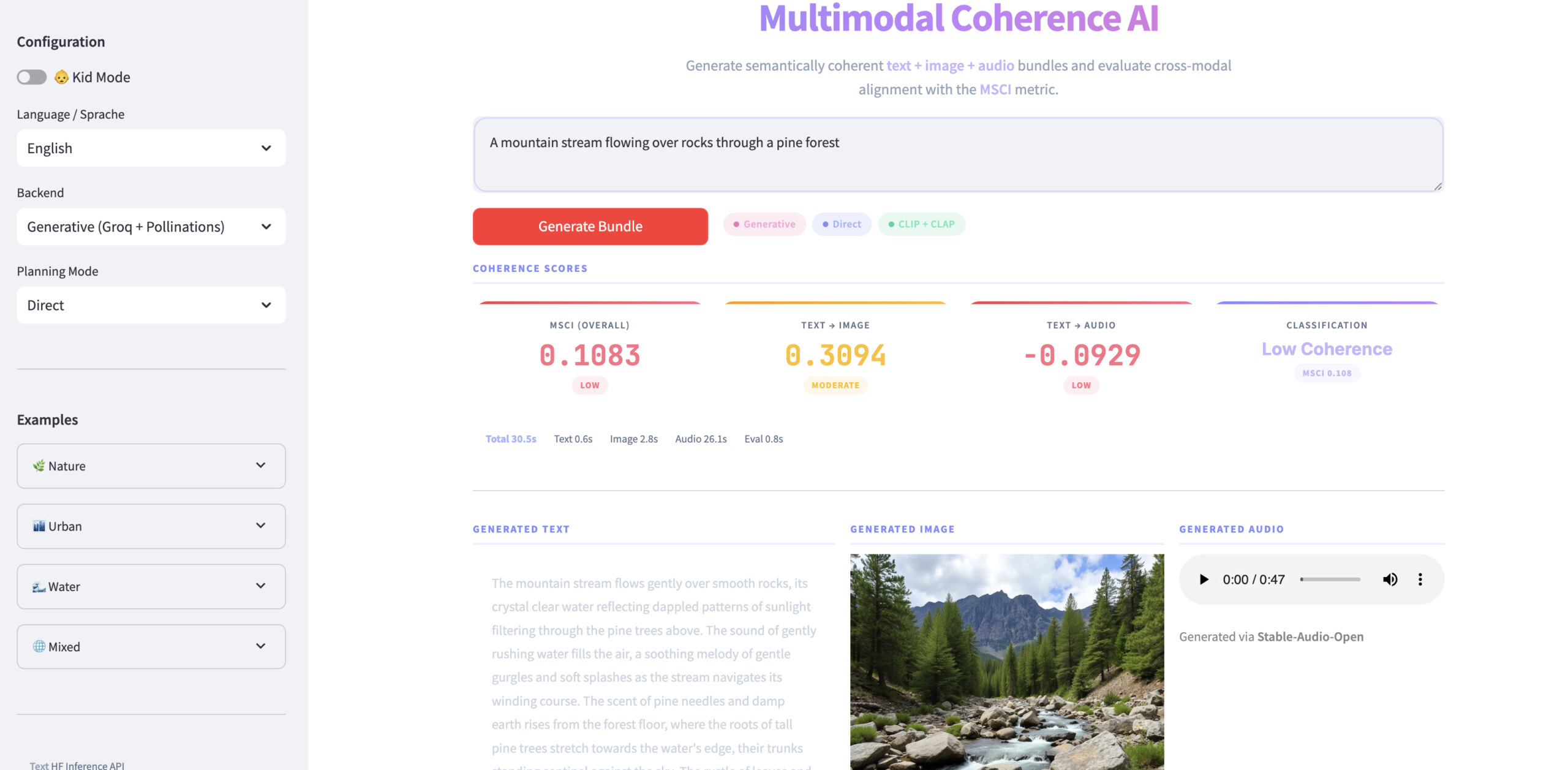
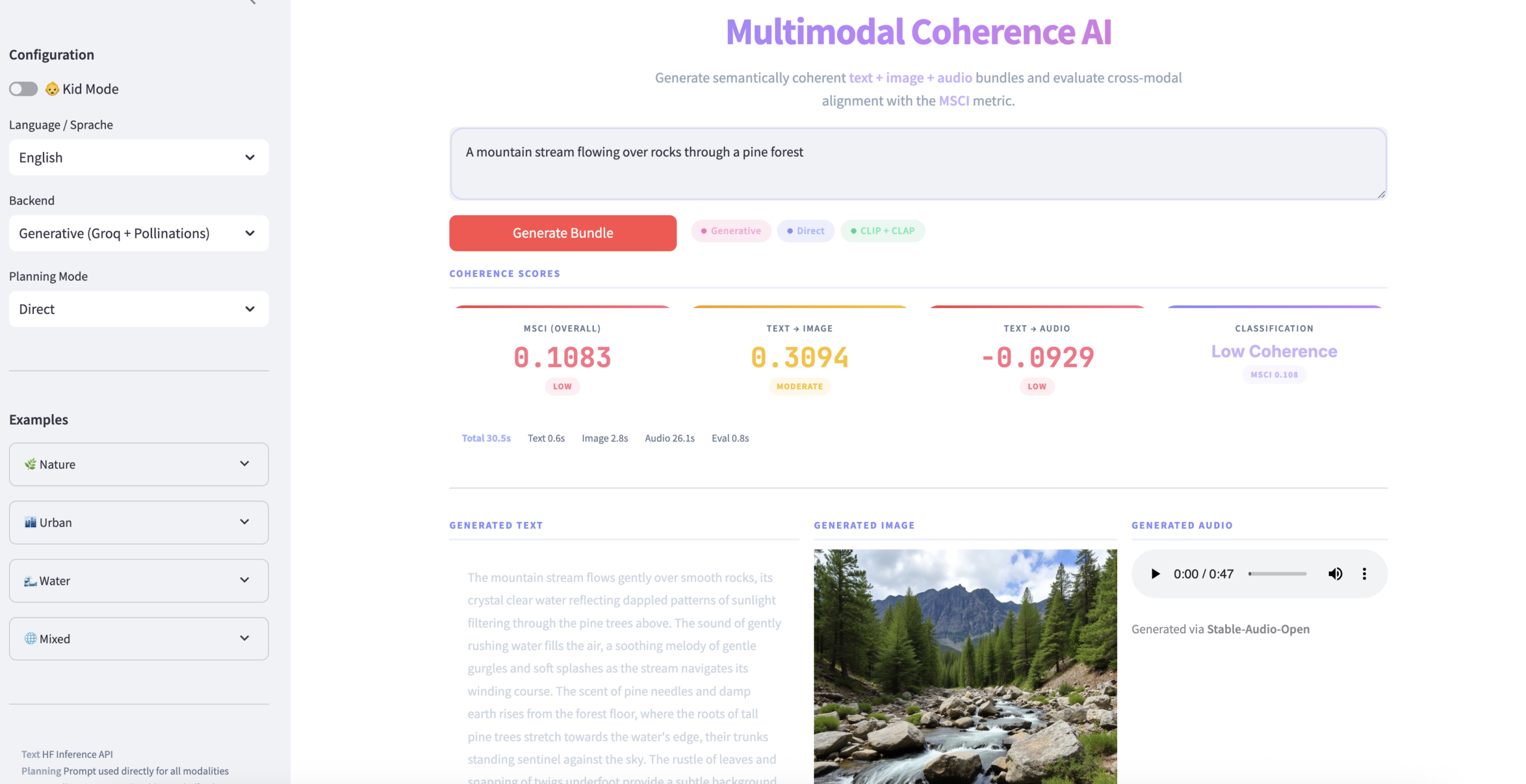
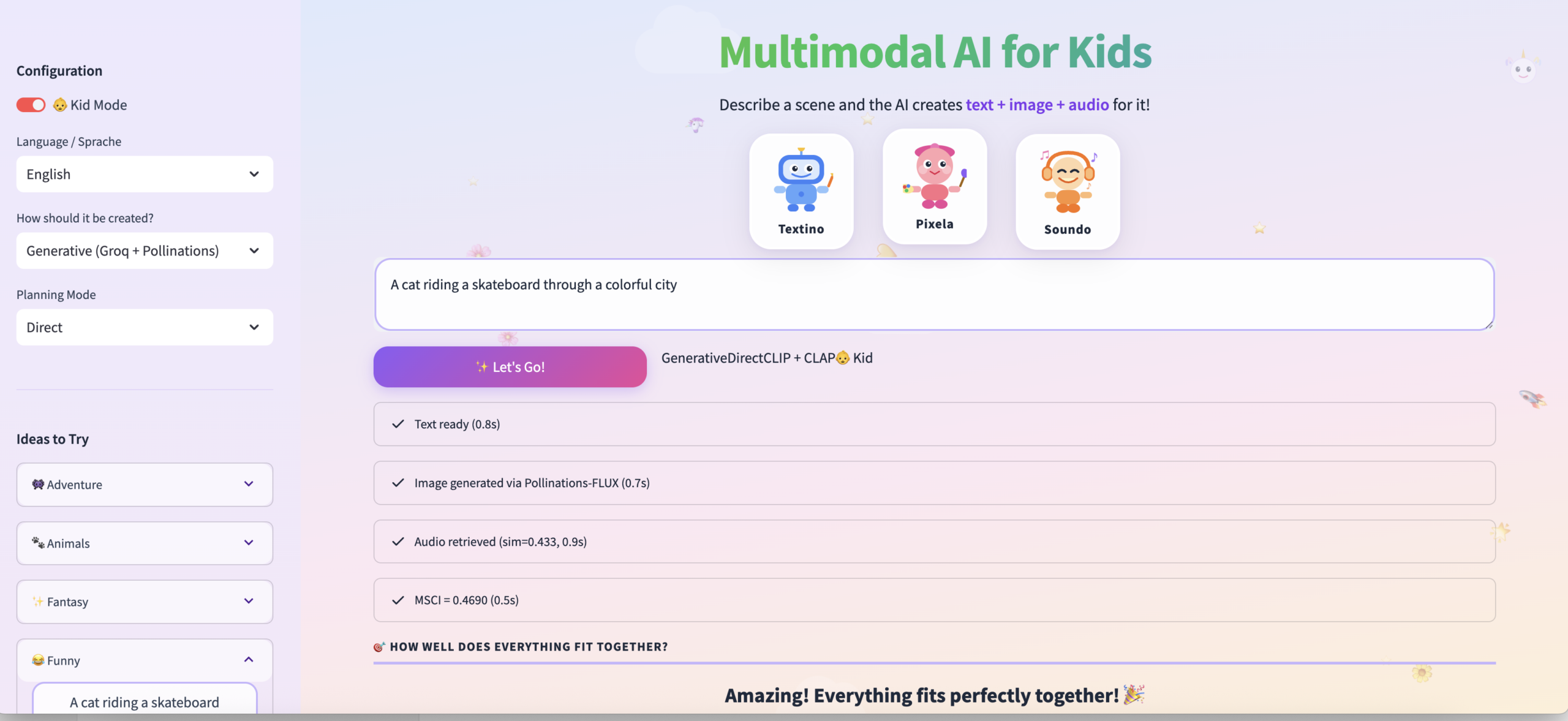
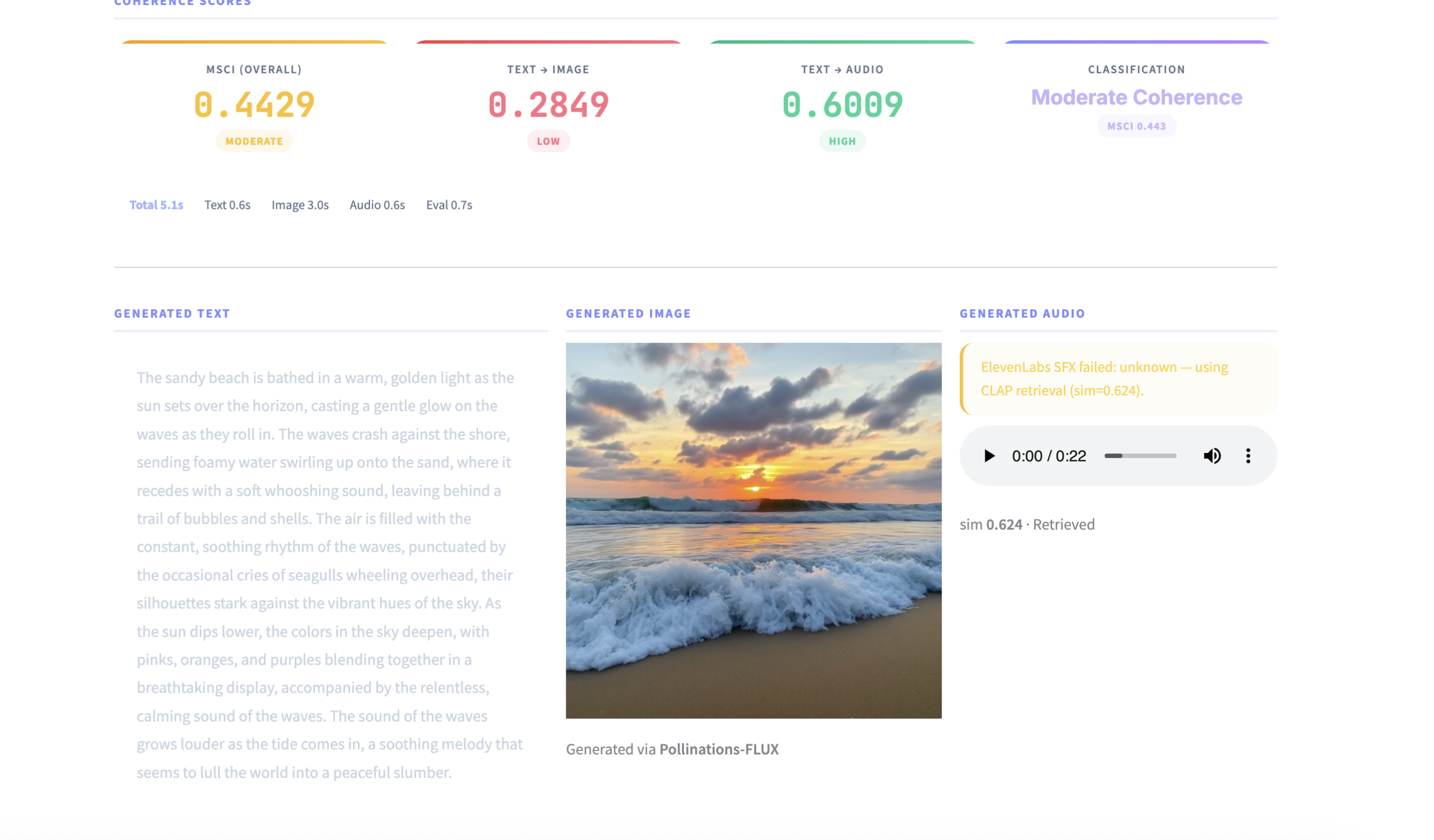
The platform serves both as a live experimental environment and as a research prototype for studying multimodal alignment, geometric distortion, and representation consistency. It can be used to explore how different modalities contribute to a unified semantic understanding, making it valuable for applications in multimodal retrieval, generative AI evaluation, cross-modal validation, and AI explainability. The project also provides a foundation for extending coherence scoring toward probabilistic and uncertainty-aware frameworks.
You can explore the live interactive demo on Hugging Face:
https://huggingface.co/spaces/pratik-250620/MultiModal-Coherence-AI
The complete implementation and research-oriented codebase are available on GitHub:
https://github.com/pratik-250620/MultiModal-Coherence-AI
This project reflects ongoing work in multimodal representation learning and can serve as a starting point for research extensions, benchmarking studies, or integration into larger AI systems.
